Today I read We Need To Rewild The Internet by Maria Farrell and Robin Berjon (April 16, 2024), and below are my personal annotated highlights from it.
Subtitle of the article, to set the tone:
The internet has become an extractive and fragile monoculture. But we can revitalize it using lessons learned by ecologists.
Concept of ‘shifting baselines’ which is useful in many other contexts when considering ‘change’:
As Jepson and Blythe wrote, shifting baselines are “where each generation assumes the nature they experienced in their youth to be normal and unwittingly accepts the declines and damage of the generations before.” Damage is already baked in. It even seems natural.
Rewilding vs. timid incremental fixes that afford no true progress:
But rewilding a built environment isn’t just sitting back and seeing what tender, living thing can force its way through the concrete. It’s razing to the ground the structures that block out light for everyone not rich enough to live on the top floor.
Deep defects run deep:
Perhaps one way to motivate and encourage regulators and enforcers everywhere is to explain that the subterranean architecture of the internet has become a shadowland where evolution has all but stopped. Regulators’ efforts to make the visible internet competitive will achieve little unless they also tackle the devastation that lies beneath.
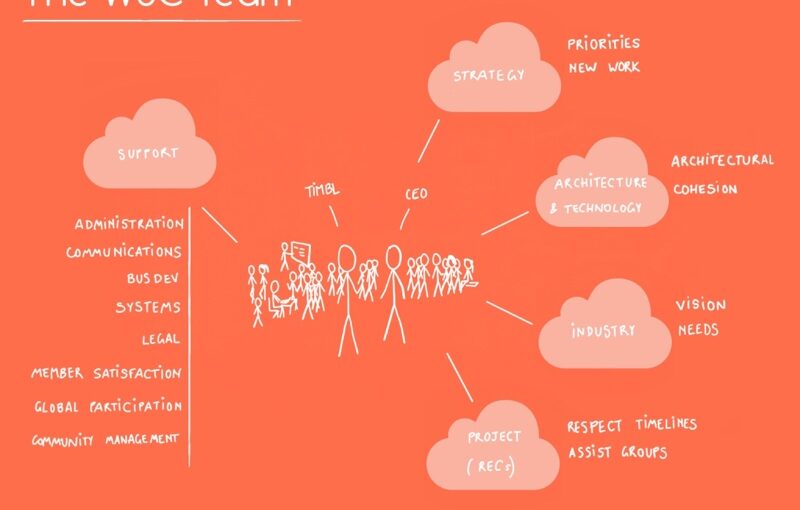
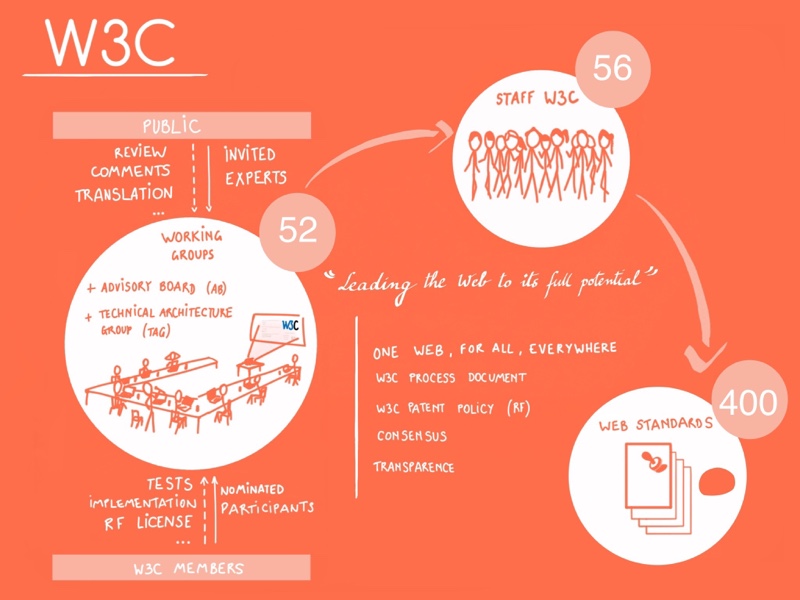
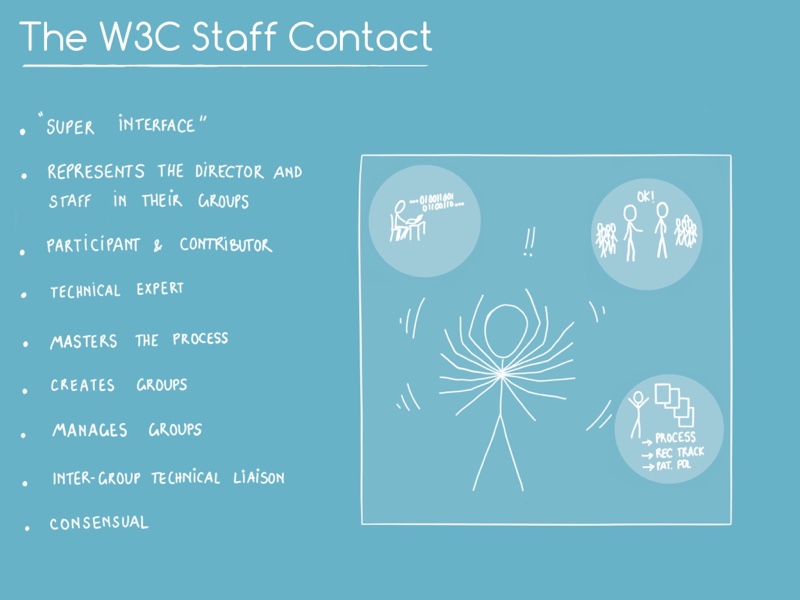
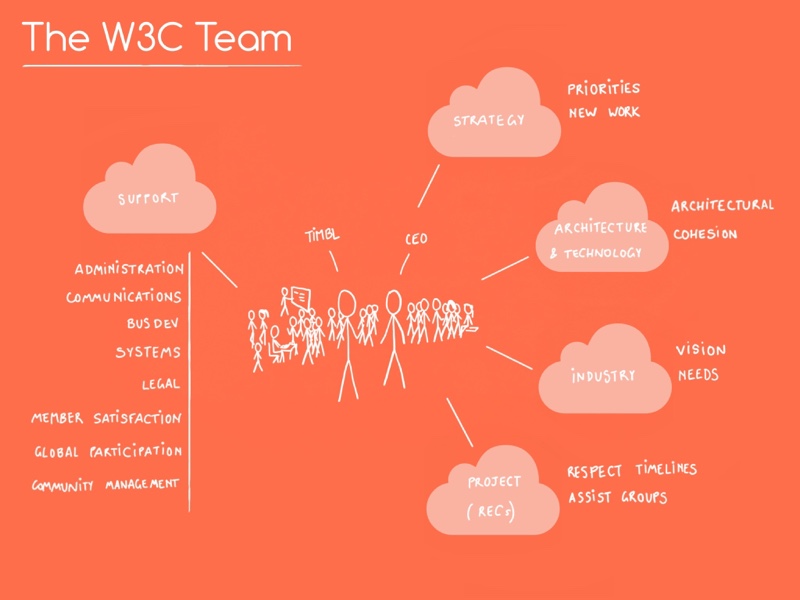
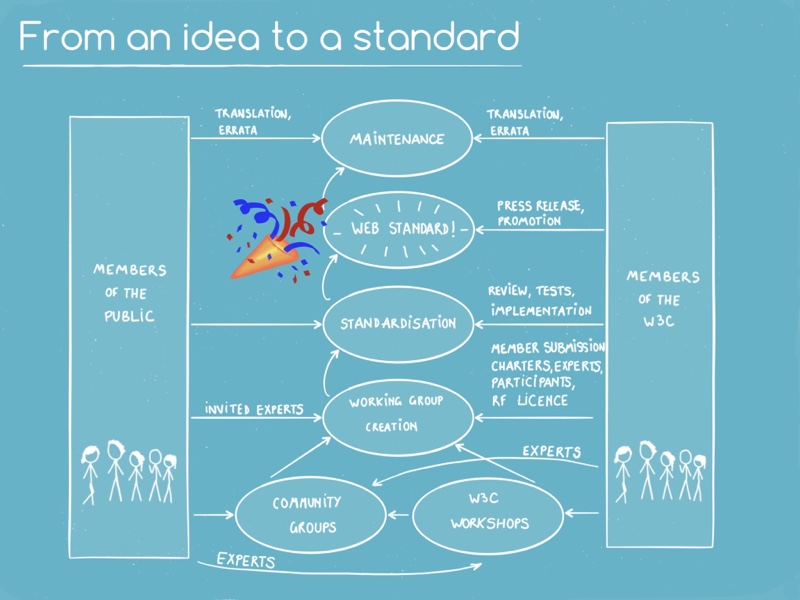
Public utilities need to be recognized as such, and funded as such (including the non-profit organization I work for, W3C, which develops standards for one application of the Internet: the Web):
[Instead, w]We need more publicly funded tech research with publicly released findings. Such research should investigate power concentration in the internet ecosystem and practical alternatives to it. We need to recognize that much of the internet’s infrastructure is a de facto utility that we must regain control of.
Better ways of doing it (also, read as a pair with the concluding paragraph of the article which I labeled ‘manifesto’):
The solutions are the same in ecology and technology: aggressively use the rule of law to level out unequal capital and power, then rush in to fill the gaps with better ways of doing things.
Principled robust infrastructure:
We need internet standards to be global, open and generative. They’re the wire models that give the internet its planetary form, the gossamer-thin but steely-strong threads holding together its interoperability against fragmentation and permanent dominance.
Manifesto (which I read several times and understood more of each time):
Ecologists have reoriented their field as a “crisis discipline,” a field of study that’s not just about learning things but about saving them. We technologists need to do the same. Rewilding the internet connects and grows what people are doing across regulation, standards-setting and new ways of organizing and building infrastructure, to tell a shared story of where we want to go. It’s a shared vision with many strategies. The instruments we need to shift away from extractive technological monocultures are at hand or ready to be built.
I am looking forward to a piece (or a collection of pieces) that will talk to the people in a manner that they hear this [understand it] and that moves them to make different choices.
Pretty much as I am doggedly and single-mindedly making different and sensible ecological choices for the planet, while I look forward to people being moved at last to durably do the same.
My thanks to Robin (who I know and work with) and to Maria (who I’d like to know now)!